The STORMM View of Coding for Molecular Science
Computational science is a practice of applying theory to scientific questions through numerical models and simulations. As such, it is best that scientists who want to develop methods have a connection to the underlying numbers, and this is best achieved with a collection of modular and open-source data structures tailored to the elemental operations of the simulation. For molecular modeling, the basic data structures are molecular topologies and coordinates, but most codes for such computations mount the data in a series of individual arrays and are built for doing one or a set number of such calculations at a time.
STORMM starts by creating its own unique classes for collecting molecular parameters and coordinates, then makes these first-class C++ classes to take advantage of all functionality in the C++ Standard Library: objects of these classes may be used in dynamic array allocation, passed to functions, returned by functions, copied, and named as the developer likes. The next step is to elaborate on the parameters and coordinates with classes to interact with them, enabling simulations, evaluate the textbook chemical structures out of thousands of atoms, and optimize compute-intensive aspects of a simulation.
For more than a decade, computational science has been transformed by vectorized, general-purpose graphics processors (GPUs). The degree of efficiency afforded by this end point of non-uniform memory access (NUMA) computing is staggering: a single consumer-grade card running on a few hundred watts can perform more calculations than megawatt supercomputers of the past built around single-core or multicore processors. The cards also deliver a much greater degree of parallel scaling: a supercomputer in 2005 might have delivered as little as 5-10% efficiency on a parallel simulation sprawling over hundreds of processors. A GPU in 2025 may utilize upwards of 50% of its available floating point instructions when propagating the same simulation.
In the modern computing environment, connecting scientists to the numbers in their calculations also means providing a transparent and simple way to transfer that information to the GPU to support kernels (functions) which carry out the algorithm of interest. GPU programming is difficult due to the nature of finding errors among thousands of threads accessing a single block of memory, designing the information layout so that cache overturn and memory traffic remain at the lowest possible levels, and managing all of the pointers that the kernels need in order to access relevant data. STORMM solves these problems with the style and standards of its C++ classes, letting them produce abstracts of pointers and critical array sizes which can be submitted to GPU kernels with much the same appearance as a function call in a C program. Furthermore, all C++ classes are built on a built-in dynamic memory format which manages allocations on both the GPU device and CPU host, as well as transfers between them. The C++ layer provides a means of organizing data and testing its veracity with minimal obfuscation as might be encountered in something like a Python program. The class abstract convention in STORMM ensures that the algorithms and ideas carry over to the GPU.
Keep Dependencies Minimal
STORMM's compilation is fast and robust due to careful construction of the CMake scripts and a low dependence on external software packages. Planning for compatibility in trajectories that it will write and other data it might store, STORMM compiles with NetCDF. For speed in CPU computations as well as versatility in a fundamental mathematical operation STORMM compiles with PocketFFT. Otherwise, rather than bring in NVIDIA's CUDA Thrust or AMD's RocThrust, STORMM uses its own Hybrid<T> dynamic memory class to manage corresponding data on the CPU host and the GPU device. Features of the Hybrid<T> class are entwined with exception handling to expedite backtracing. Another built-in dependency bypass is the unit testing library, including the TestEnvironment class which rolls together customizable command line input with runtime success and failure tallies as well as test summary output. The testing functions replicate the essential features of popular unit testing packages with specializations for the sorts of computations common to computational chemistry. Having all of these features rolled into a single code base also presents developers with a unified resource, the STORMM doxygen documentation, to delve through when looking for particular methods and data structures.
C++ to C, and then to CUDA
STORMM is built to run NVIDIA's CUDA for the time being, although the code is prepared for a transition to some agnostic state with respect to the high-performance computing language in the future. The workflow for porting a new algorithm or memory structure to the GPU is illustrated in the following diagram. Starting with a C++ class containing data in Hybrid<T> dynamically allocated arrays (as opposed to the C++ Standard Template Library std::vector<T> dynamic memory allocation system), a class method is written to return a struct containing critical array size constants and pointers to the relevant memory. If the class contained std::vector<T> arrays for its memory, a set of pointers to each array's .data() member variable and constants for its .size() would, in effect, allow the developer to traverse the class object's data as if it were a C struct object. In STORMM, there is an additional choice to make: while the size of any given array will be the same on the CPU or on the GPU, the pointers can refer to data on the CPU host or on the GPU device. The developer can still traverse the host-side data as if it were a C struct, but also take the abstract with pointers to memory on the device and traverse it with C-like CUDA.

In the above diagram, a hypothetical STORMM class contains five Hybrid arrays in two different data types, e.g. int and double. It also contains a pointer to another object of the STORMM topology type (this is called AtomGraph in the code, but that detail is irrelevant here), as a way to trace the original inputs used to create / calculate its contents. This pointer is only valid for the CPU, and therefore doesn't become part of the abstract. Each of the Hybrid arrays, however, hold valid pointers to data on the CPU host as well as on the GPU device, so the abstract is created based on a choice of whether pointers should be directed towards data on either resource to facilitate computations there. The StormmClass also contains a tuple of three extra parameters, i.e. three double values, which are included in the abstract as constants. The abstract is a key to the data in the class--if the values of the tuple are changing over time, the convention in most STORMM classes is to have the abstract be a snapshot of the class at any given time, with const qualifiers on such values to treat them as constants.
Syntheses: Not Just Arrays of Topologies or Coordinate Sets
It's easy to think that the way to stage multiple problems on the GPU is to create arrays of the basic AtomGraph topology or PhaseSpace coordinate and force-holding objects. However, this is bad for two reasons: first, for engineering safety, the Hybrid<T> data type is restricted to various elemental data types, e.g. double, char, or unsigned int. It cannot be used to create an array of topologies or coordinate objects, and even if it was then there would be host- and device-level pointers to the host- and device-level elements of each topology or coordinate set in the list, which would only be valid if accessed in particular ways. A more mundane form of pointer acrobatics gives rise to the second, performance-centric reason: a list of objects with their own sub-arrays would require threads in a GPU kernel to de-reference the list pointer and then the array pointers of the underlying objects. A list of abstracts would do no better. It's a cost to de-reference a pointer, which is why optimized codes like to get into an array and then go straight down all of its elements to utilize all of the vectorization the chip can muster. In C++ code, it's easy enough to store a temporary pointer to the location of interest and cut through a series of pointers in that manner, but storing a temporary pointer exacts a cost in registers which are in short supply on the GPU (this, more than cache rationing, is perhaps the most significant distinction in GPU program optimization). The GPU should be directed to as few arrays as possible, and a always given means of striding through them from start to finish.
A synthesis of topologies or coordinates is therefore a new class which has similar numbers of member variables to the corresponding classes for a single system, but collates all systems' data of a particular type, e.g. all x coordinates or all atomic partial charges, into a single array. Padding is applied between systems to ensure that one warp accessing the data will read a single cache line. The synthesis of topologies, AtomGraphSynthesis, stores a series of integer markers to indicate where each system's details start and stop, as does the coordinate synthesis, the PhaseSpaceSynthesis. The arrangement, and the contrast between a synthesis and an array of objects, is illustrated in the following diagram:
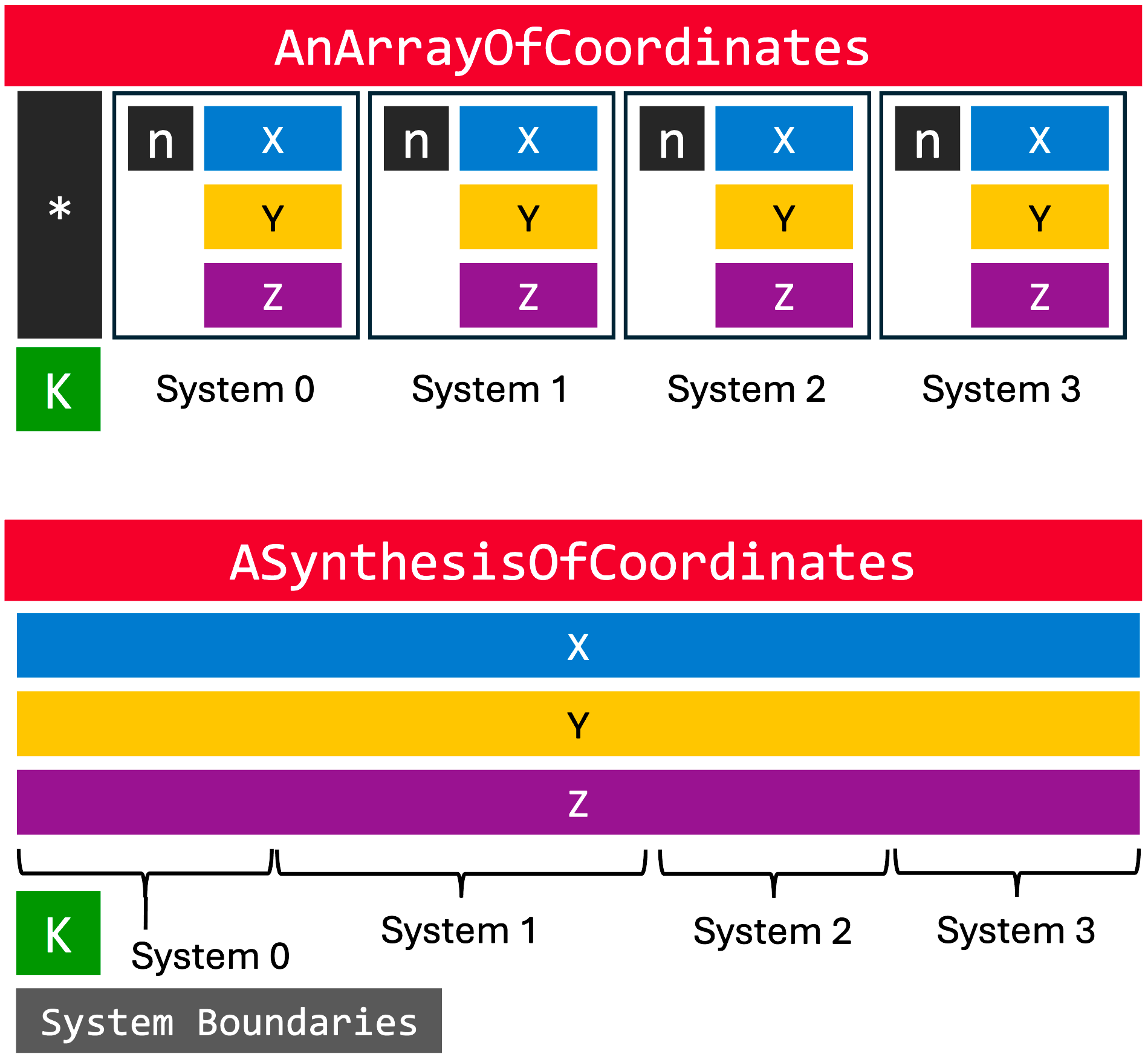
Above, a series of molecular coordinate objects is first arranged in a traditional array. It could be a std::vector<Coordinates>, but this would be cumbersome to port data to and from the GPU for reasons already mentioned. The essential elements are the allocated data for the array elements, the sub-allocations for atomic positions and the number of atoms within each coordinate object, and the number of molecular systems in the array. In contrast, the synthesis of such systems arranges all Cartesian x, y, and z coordinates into their own arrays, and might store an additional array of tuples containing the first and final array elements at which to find the positions of atoms in each system. The number of systems K, dictating the length of the bounds array, is likewise stored. While the above example reduces the number of pointers three-fold, in principle any number of systems' coordinates can be stored in a synthesis of the same format, whereas the array of coordinate objects continues to require 3K + 1 pointers.
The purpose of a synthesis is to establish a framework for the GPU thread blocks to stride down contiguous arrays of data in order to perform the same calculation on every system in the series. The individual steps taken by the GPU are also planned by the CPU, often assembled into arrays of their own class objects, as described in the final section.
Work Units: The CPU Delegates to a GPU Vector Engine
In order for the GPU to function efficiently on a heterogeneous set of problems, not just a stated number of replicas of a similar problem but a diverse set of simulations that could range in size from 500 to a million atoms, STORMM breaks down all problems into the smallest common element, the lowest common denominator. In our paper, these elements are termed work units. One of the most intricate examples of work units in the code base, discussed in the introductory publication, is the valence work unit, with several classes devoted to its construction. Other work units may be tuples of even bit-packed arrays of unsigned int. Work units are instructions to GPU kernels, detailing what information to access in order to perform the next iteration of the kernel's main loop, whether that is to evaluate a particular dihedral interaction between four adjacent atoms or all pairwise interactions among two lists of atoms subject to exclusions enumerated in an array beginning at a specified index.